Update May 20, 2024
As usual, we've been running pretty fast in the past few weeks. Several big things have landed, and we'll talk about them here today. Sprinkled throughout, are a whole host of tiny improvements, bug fixes, and all kinds of good stuff. Small things, even if they aren't mentioned in the fancy updates, are a big deal. They are what makes a good product.
🧑💻 Build API
The code-first approach has been the primary method of building boards in the early days of Breadboard, and it may have started feeling a bit underappreciated with all the buzz around the Visual Editor.
This changes with the release of the Build API: a new, more TypeScript-idiomatic take on building boards with code.
The Build API aims to provide a lot more type safety (the "red squigglies" as we call them), and reduce the amount of guessing of what will and won't work when creating a graph with code.
To make this API possible, we've done quite a bit of groundwork, incorporating all the learnings from our first two previous iterations on the syntax.
We even came up with a Breadboard Type Expressions (BTE) system that acts as a bridge between JSON Schema types, and TypeScript types.
// Defines a type that represents an object...
const imagePartType = object({
// ... with a property "inlineData" that's also an object ...
inlineData: object({
// ... which contains a property "mimeType"
// that's an enum of common image values ...
mimeType: enumeration(
"image/png",
"image/jpeg",
"image/heic",
"image/heif",
"image/webp"
),
// ... and a string property "data".
data: "string",
}),
});
// Returns the following JSON schema:
// {
// "type": "object",
// "properties": {
// "inlineData": {
// "type": "object",
// "properties": {
// "mimeType": {
// "type": "string",
// "enum": [ "image/png", "image/jpeg", "image/heic","image/heif", "image/webp" ]
// },
// "data": { "type": "string" }
// },
// "required": [ "mimeType", "data" ],
// "additionalProperties": false
// }
// },
// "required": [ "inlineData" ],
// "additionalProperties": false
// }
const schema = imagePartType.jsonSchema;
// Returns the following TypeScript type:
// {
// inlineData: {
// mimeType: "image/png" | "image/jpeg" | "image/heic" | "image/heif" | "image/webp";
// data: string;
// };
// };
type ImagePart = ConvertBreadboardType<typeof imagePartType>;If you are familiar with Zod, it will look familiar. The biggest difference is that BTE focuses on bridging the two type systems, rather than providing a programmatic way to define TypeScript types and validation.
Thanks to BTE, we are able to provide type information right at your fingertips. So when building a graph in Visual Studio Code, for example, the editor will warn you (with "red squigglies") if the wiring is wrong.
In the Build API, we also have a somewhat more elegant way of writing cycles. Because Breadboard graphs may contain cycles, the need to express them confounded the designers of the first two iterations of the API.
In this iteration, cycles must be declared ahead of time, using the loopback function. It is used to create a wire port whose value will be provided at some later time.
import { loopback } from "@breadboard-ai/build";
// Declare the loopback: a "virtual" wire that is temporarily dangling.
const bPlaceholder = loopback({ type: "number" });
// Connect the loopback to the node.
const a = someNode({ value: bPlaceholder });
const b = someNode({ value: a.outputs.result });
// Resolve the loopback by providing the missing cycle link.
bPlaceholder.resolve(b.outputs.result);The Build API comes with a whole bunch of other goodies, like the input function, which enables developers to work directly with the input node ports:
const word = input({ description: "The word to reverse" });The Core Kit, upgraded with the Build API, also has a few handy helpers, such as the template tagged literal function:
import { prompt } from "@google-labs/template-kit";
import { input } from "@breadboard-ai/build";
const dish = input();
const steps = input({ default: 10 });
const instructions = prompt`Write a ${dish} recipe in under ${steps} steps`;🎨 Visual Editor
The visual editor improved so much that it might as well be a different product. We've been steadily pouring love and care into it, and we're pretty darned happy with how it's turning out.
Nodes can have icons
Nodes can now have icons associated with them, to help better distinguish what node we're working with.
![]()
We also added a quick node selector that uses these icons to provide a way to quickly grab and create new nodes.

Select, copy, paste nodes
We can now select, copy, and paste nodes.
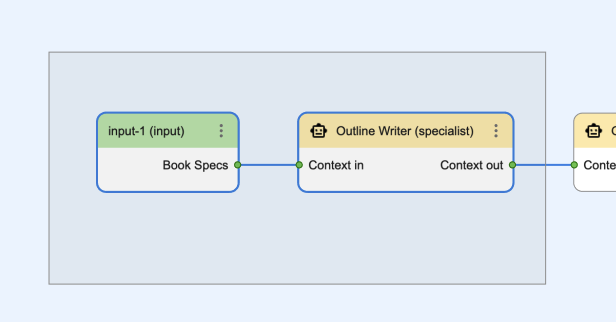
One by one, some, or all, and as many times as we would like. We can even turn our graphs into art. Not necessarily the intended purpose of the Visual Editor, but hey -- why not.
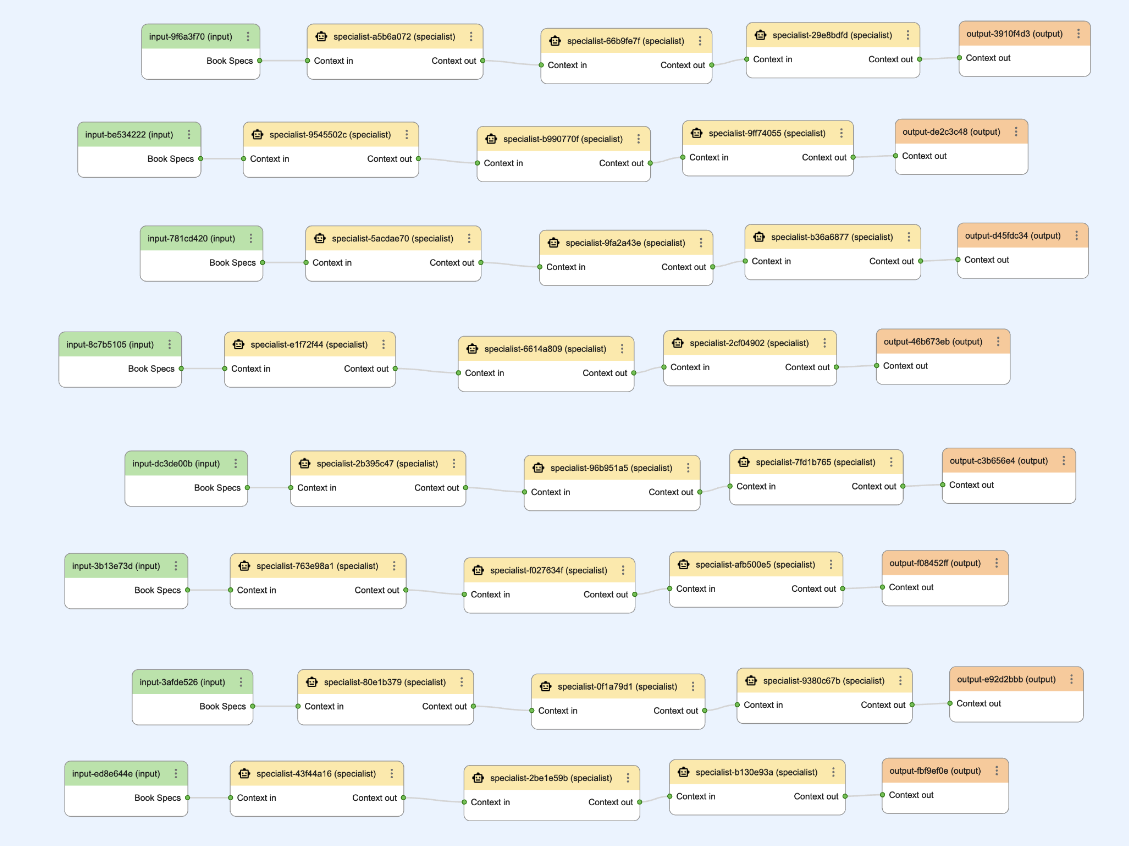
This is kind of a big deal for the Visual Editor. The ability to quickly duplicate and tweak nodes has long been on our minds, and this new capability moves us much closer toward that goal.
As a result of this change, the default behavior of the Visual Editor has changed to align more closely with other canvas-centric apps. We can now:
-
Click and drag the cursor to select nodes and edges
-
Use the mouse wheel to move around the canvas
-
Use Command/Ctrl + mouse wheel to zoom in / out of the canvas
-
Drag boxes to select multiple nodes & edges
-
Command/Ctrl + click to toggle select nodes & edges
-
Shift + click to add nodes & edges to a selection
-
Space + click drag to move around the canvas
LLM Content editor
Just a sneak preview in the last update, the LLM Content editor is now the workhorse of the rapid prototyping with LLMs. It's like a Swiss-army knife of content: it will help you add all kinds of content to your prompts and system instructions. It supports audio (as file and as microphone input). It supports video (as file and as webcam input). It supports images (as file, webcam, and drawable surface). We're still teaching the LLM Content editor to support PDF files, and that is also coming.
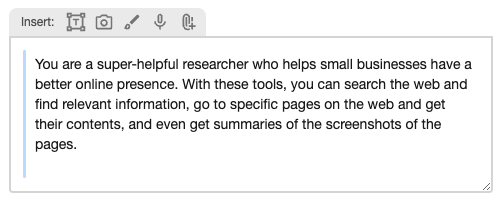
Your text input is captured as multiple parts, each of potentially different modality, and you can arrange the order of parts to craft the prompt precisely
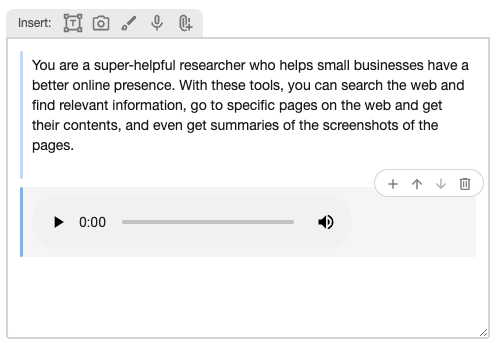
Under the covers, the LLM Content editor represents the Content object in structure. So, when the user works in the LLM Content editor, they are actually very close to the metal of the underlying API call. We call this concept "honest prompt editing", where we try to connect the user as closely as possible to what will be actually sent to an LLM API.
LLM Content output
A read-only twin of the editor is the LLM Content output, which presents the LLM Content in a friendly way. It shines particularly brightly when given multi-turn conversations, showing us the entire conversation in a neatly tabulated -- turn-by-turn -- format.
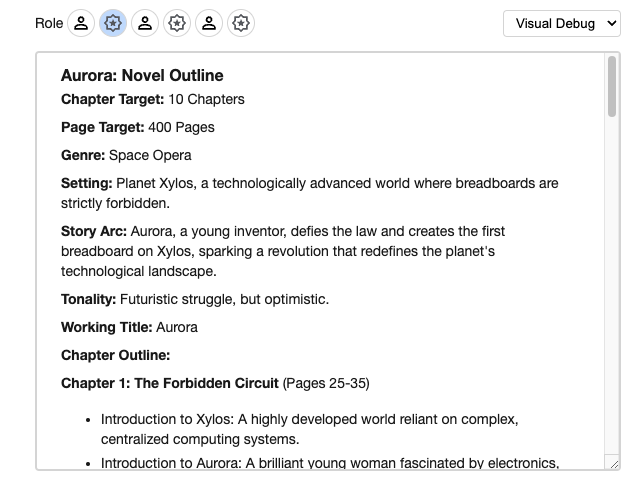
And we can still get raw JSON if we flip the mode to "Raw Data"

When used in the debugger, the LLM Content output becomes a very powerful tool for quickly examining, finding potential problems, and iterating.
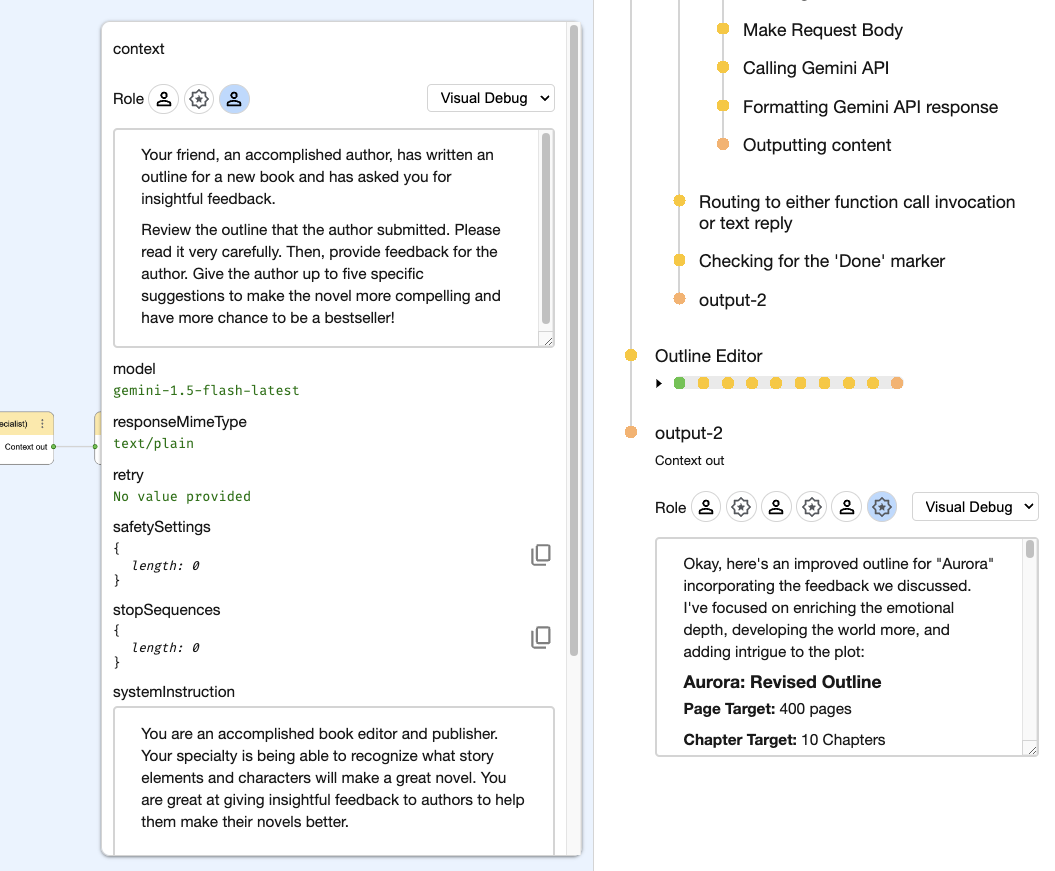
Friendlier schema editor
The JSON Schema editor has gotten an upgrade, becoming more friendly to use. The advanced options are now hidden by default, making it easier to understand. The fields moved closer together, needing less mouse movements to operate.
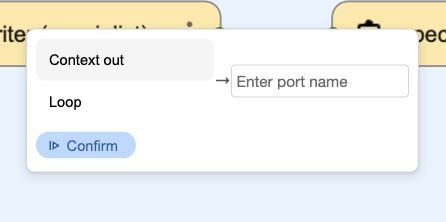
Better wiring UI
We taught Visual Editor to help users disambiguate node wiring with a helpful route selector. This one is so handy that we can't imagine how we ever made boards without it.
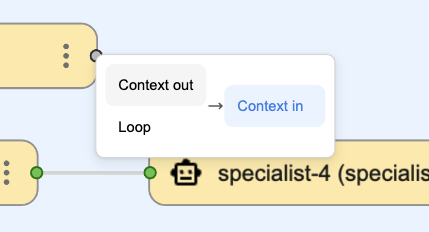
When a node allows adding ad hoc port, the route selector provides a way to add a new port.
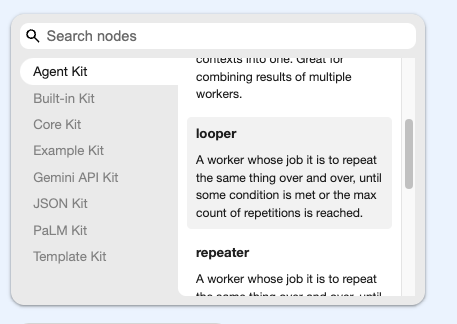
Descriptions in node picker
Finally, the node picker now has descriptions of the nodes, so that we can learn what a node does before choosing it.
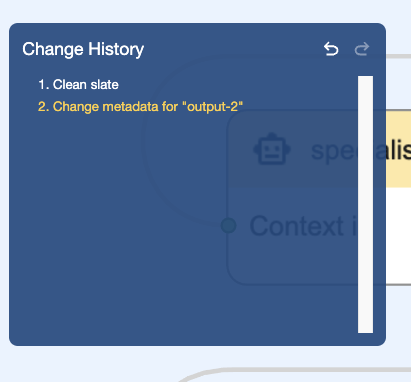
Change history (undo/redo)
The visual editor also grew the change history capability. We can now undo and redo changes with the familiar Command/Ctrl+Z and Command/Ctrl+Shift+Z. Our little baby is growing up! 🥹
✨ And more...
The alarming length of this manuscript tells us that we: a) need to send this update more often and b) this project is moving at such a rapid pace and we're having so much fun that we might still forget to do so.
Just a quick mention of things that didn't fit into this update: there's so much cool stuff happening in the Agent Kit that it deserves its own newsletter. We've been mostly quiet about it (other than going gaga in Discord), but it might be time for a reveal.
We've been also thinking a lot about how to deploy boards, and have this idea of a Board server. It's still very early, but you know us -- in a couple of weeks, it might already be humming.
Another thing we're planning to do is easier onboarding. Because of its rapid pace, this project has been somewhat difficult to get into, and now that we have most of the big pieces in place, expect more onboarding materials to start appearing.